使用Node.js实现动态爬虫
本文是关于自己用Node.js实现动态爬虫的一些记录以及踩坑。
起手式
第一个问题就是爬虫的语言选择。根据个人喜好以及之前写过的很多demo,编程语言以及模块毋庸置疑是选用当前最好的headless Chrome js依赖puppeteer了,在此之上考虑并发问题所以选用puppeteer-cluster.
puppeteer的操作一般都是基于功能强大的page来操作的。一些常见的api如$,$$(相当于querySelector,querySelectorAll),evaluate等基本保证我们快速实现定位元素以及在浏览器的context下执行javascript 的功能。这次写的时候还另外注意到原来ElementHandle类(即使用$,$$得到的node)也可以直接evaluate,这样就节省了很多不必要的操作。
第二个问题是,我写这个爬虫希望达到的效果是什么(因为老实说写项目这点上自己更多是任务驱动而不是主观上希望实现什么)。从最终结果来看,我认为大体上是以搭配被动扫描器为目的,即把扫描器作为crawler的代理。这样的话,爬虫的要求就应该是尽可能多的触发事件,尽可能多的搜集url。
目前看来github 上比较受欢迎的是 crawlergo 跟 LSpider,各有特色。我个人主要是按照LFY的思路以及几篇参考文章实践的。
初始化
puppeteer 的启动参数上,主要是注意关闭XSS Auditor并允许不安全内容。当然还有比较重要的关gpu,no-sandbox等等,主要是为了节约资源。
{
"puppeteerOptions":
"args": [
"--disable-gpu",
"--disable-dev-shm-usage",
"--disable-web-security",
"--disable-xss-auditor",
"--no-zygote",
"--no-sandbox",
"--disable-setuid-sandbox",
"--allow-running-insecure-content",
"--disable-webgl",
"--disable-popup-blocking"
]
}然后就是常规的page设置。UA设置为随机UA不必多说,比较重要的是开启request拦截以及注入hook代码。这些会在下面谈到。
hookJS
我们需要在dom构建之前就hook Javascript。这一步的目的当然是为了在dom构建之前就尽可能多的收集url.所以上面使用await page.evaluateOnNewDocument(hookJS);来在页面加载前注入 JavaScript 代码。
具体hook思路很简单,一些有可能导致页面重定向或者阻塞的函数如window.open或window.close,我们把它hook了;(其实弹窗也会阻塞,不过我们有专门的api来关闭弹窗。)一些参数里有url的我们获取到参数存起来然后正常执行;一些像超时的代码如setTimeout,setInterVal我们把它时间控制在1s多。 (注意这两个函数参数都是ms)
除此以外还需要hook 事件注册。刚好借此学习到了事件注册的两种方式。
一种是早期的dom0注册
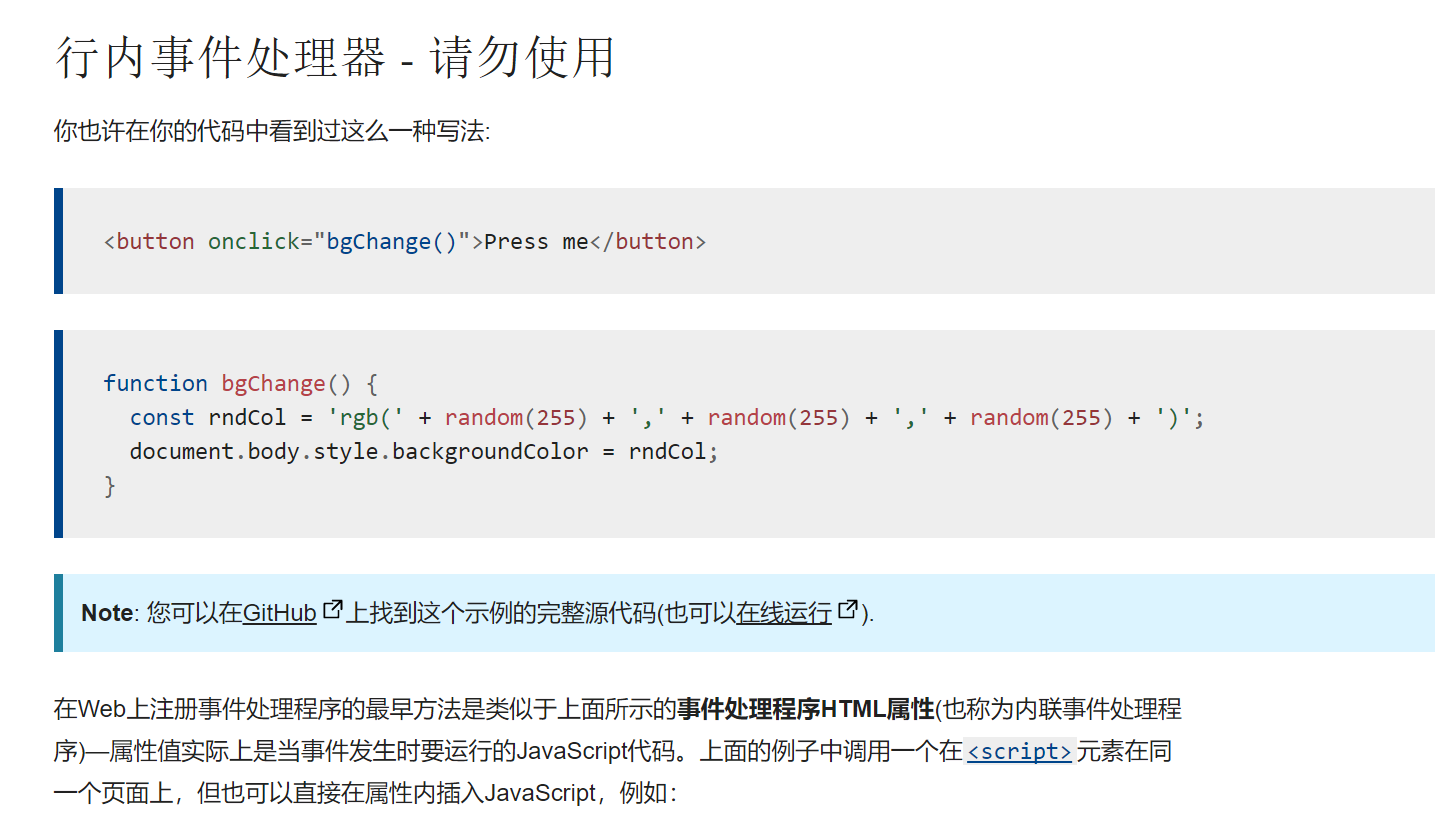
当然这种方式已经过时了,所以我所了解到的更多是第二种注册方式addEventListener,即dom2级注册。
function bgChange() {
const rndCol = 'rgb(' + random(255) + ',' + random(255) + ',' + random(255) + ')';
document.body.style.backgroundColor = rndCol;
}
btn.addEventListener('click', bgChange); 所以hook两种事件的方式当然就不同了,前者是设置访问器属性,后者直接hook addEventListener原型即可。
具体参考 https://www.anquanke.com/post/id/178339#h2-2
这里hookJS 执行的context是在浏览器,不能在代码里直接通过global等方法获取到hook的url.所以方法就是hook时把结果存好,比如存到window里,额外page.evaluate( () => return window.foo)即可。
hook Navigation
前端导航是这次自己困惑最久的地方。本身也是一个难点。从 https://www.anquanke.com/post/id/178339#h2-7 这里可以知道,我们一般希望自己的页面不会随便就跳转,但是hook window.location是不可行的,因为默认location属性的configurable选项是false。
文中提到一种,由于开启了interception,只要修改返回值为204就好了。
204意思是,服务端说明操作已经执行成功,同时告诉浏览器不需要离开当前的文档内容
但是我在自己尝试时发现,并没有达到预期效果。例如:
<script>
window.location = '/test1';
window.location = '/test2';
window.location = '/test3';
</script> 对于上面这个例子,理论上我们必须获取到三个跳转链接。然而实际上无论是开拦截还是人工开这个页面,浏览器都只会执行最后一个跳转。因为前两个都会被下一个跳转中断。
最终权衡了下,使用了https://github.com/myvyang/chromium_for_spider/releases 这里重新编译源码的chromium。它把上述前端导航的url全都锁到window.info 里了。解决了问题,但是windows下就不能用了。。。。。。
改用dalao的 https://github.com/myvyang/chromium_for_spider
修改过源码的爬虫后。页面默认不会跳转了,并且待跳转的url直接在window.info里。
另外需要实现的是,对于请求里包含图片资源的,我们需要返回自己的图片避免不必要的加载。对于包含logout请求的我们把它abort掉。因为如果爬虫的cookie因为logout清除了就会导致爬的信息变少。所以需要处理。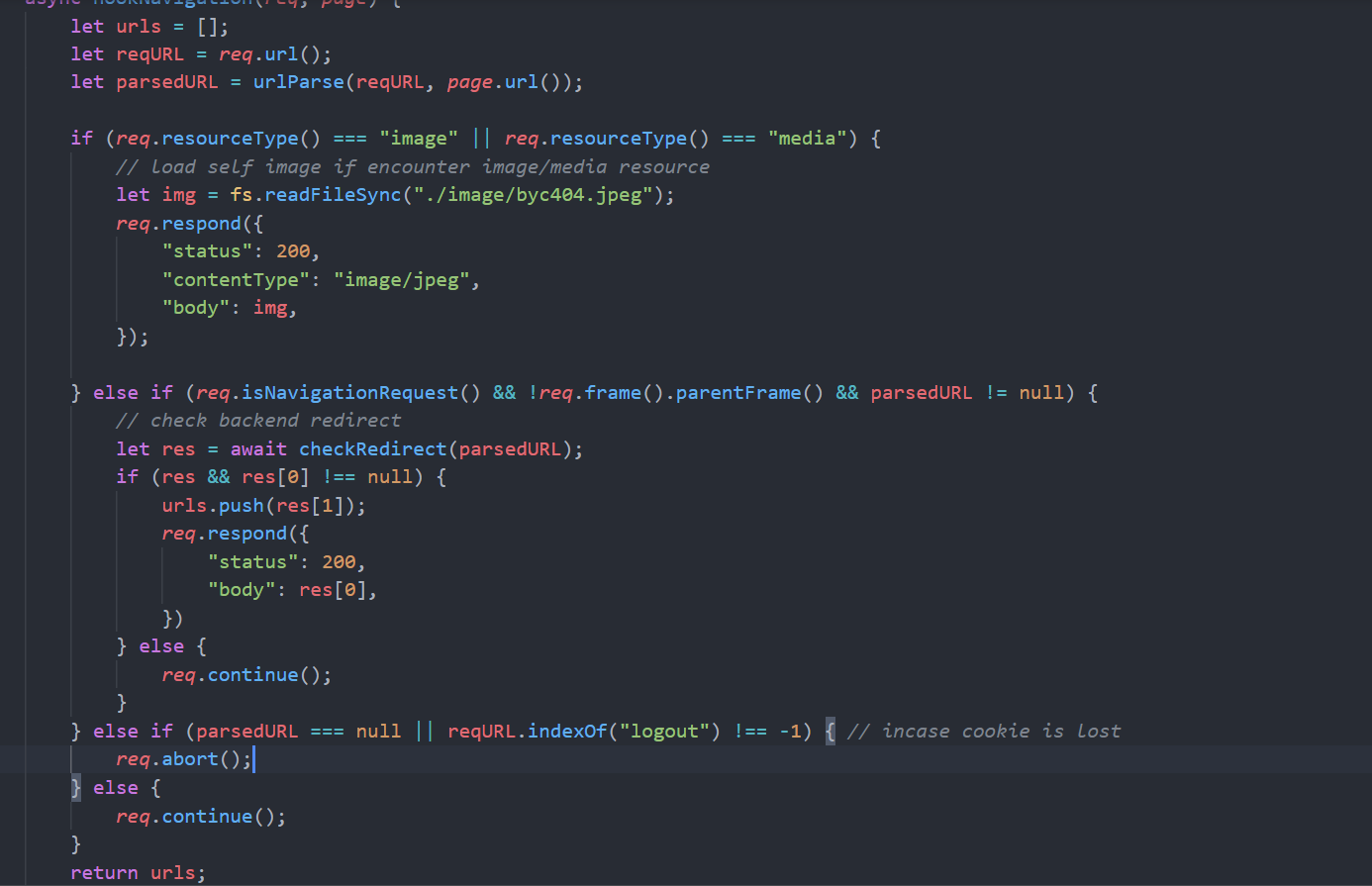
还有一个坑,我们想达到的目的是:
前端重定向全部取消,并记录下目标链接放入任务队列
后端重定向响应的body中不包含内容,则跟随跳转
后端重定向响应的body中含有内容,无视重定向,渲染body内容,记录下location的值放入任务队列
这里针对后端跳转, 由于我采用的是监听response 事件,所以响应其实应该已经返回了。这不足以做到body中含有内容不跟随跳转。所以还是得自己实现,这里我用node-fetch来判断返回内容。无内容直接跟随,有的话就手动设置响应状态码为200。
收集link && 注释
这一部分做的是收集各种dom构建好之后的link与href等等会包含的url.之后也会将其加入到队列中,做起来还是比较轻松的。
const links = await page.$$eval('[src],[href],[action],[data-url],[longDesc],[lowsrc]', getLink);
这里需要注意的是base标签是否存在。如果有base标签的话优先把base作为整个page的baseURl载入,然后收集各种链接(可能有相对链接)parse即可。nodejs 的URL类构造函数接收的两个参数刚好就是input和base,比较好的解决了相对链接的问题。
然后是comment 的识别。有时候注释里会存在隐蔽的接口,往往是解决问题的入手点。这里用xapth识别出来并且正则匹配出url即可.比较尴尬的是正则只能匹配完整的url,因为玄学问题没匹配到相对路径,遂放弃。
表单输入以及提交。
表单信息的填写以及提交。这里其实还好,没啥坑。主要就是根据各种表单类型,输入类型来常识性的fuzz一些可能导致漏洞的输入,比如尝试sql注入等。
具体代码实现中,我们可以先用$$拿到表单的node.对于每个表单node我们去获取它可能的输入,包括input, select, textarea, datalist等。根据不同类型的node,我们的处理当然不同。但是能输入文字的当然是尝试一些fuzz性质的输入。假如这个node的输入类型是可以推断的,我们就尽可能输入比较合理的内容。例如需要输入邮箱的地方,class,name,id等等可能会包含email,我们提取出来就可以输入了。
此处学到的一个想法是,对于表单提交我们可以另外开一个iframe,接收表单提交。由于这里chromium已经锁住各种导航了,提交的url我们当然也能收集到。
事件触发
事件触发的思路就是,尽可能去触发所有已注册的事件。
- dom event trigger
对于最早hook的dom event, 我们直接触发。由于最早hook js时已经收集过一些dom 的事件了。所以这里直接提取,用dispatchEvent触发即可。
let newEvent = document.createEvent('CustomEvent');
newEvent.initCustomEvent(event["eventName"], true, true, null);
event["element"].dispatchEvent(newEvent);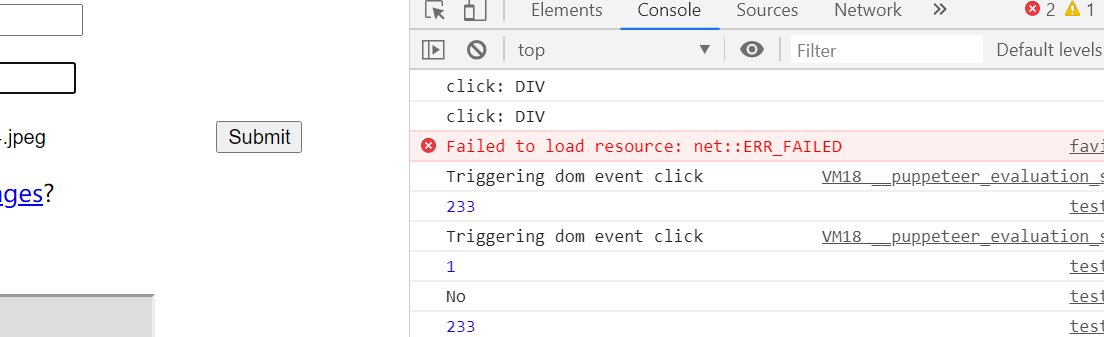
- inline event trigger
除了dom事件触发,我们还需要触发内联事件,什么是内联事件呢?这里存在一个事件捕获与冒泡机制的问题。
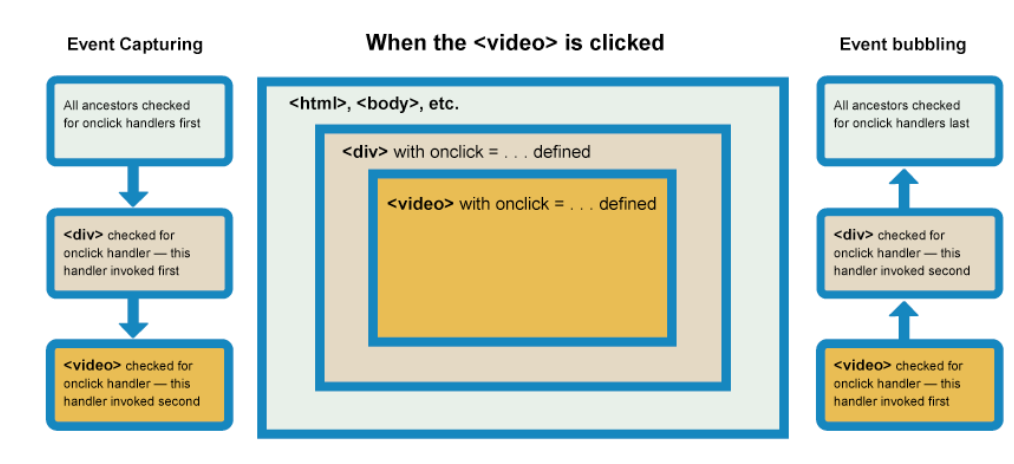
浏览器检查实际点击的元素是否在冒泡阶段中注册了一个onclick事件处理程序,如果是,则运行它
然后它移动到下一个直接的祖先元素,并做同样的事情,然后是下一个,等等,直到它到达<html>元素。
(跟dispatch的机制有点像。)
默认情况下,所有事件处理程序都在冒泡阶段进行注册。所以事件会存在一个propogate的过程。我们假如给某个嵌套div的最外层注册了事件,那么点击它的子节点其实也会触发这一事件。
所以,这里我们对于内联事件的处理方式是:先按照常见事件获取到节点。触发完后,对其每层子节点也尝试触发下,这个层数限制是3层。
const fireInlineEvent = (node, eventName) => {
console.log(`Triggering Inline event ${eventName}`)
let event = document.createEvent("CustomEvent");
event.initCustomEvent(eventName, false, true, null);
try {
node.dispatchEvent(event);
} catch (err) {
console.log(err);
}
}我们initCustomEvent的第二个参数是canBubble.代表它是否会冒泡。
这里关掉headless看下效果如何。我的测试页面是
<div id="div1" onclick="console.log(1)">
Test Div1
<div class="a">
Div1 Child1
<div class="b">Div1 Child1 Child1</div>
</div>
</div>
<div id="div2">Test Div2</div>
<script>
div2.onclick = () => console.log(233);
div1.addEventListener('click', function setup(e) {
console.log('No');
});
</script>可以看到触发了3次。且后两次由于没有冒泡并不会触发console.log(1)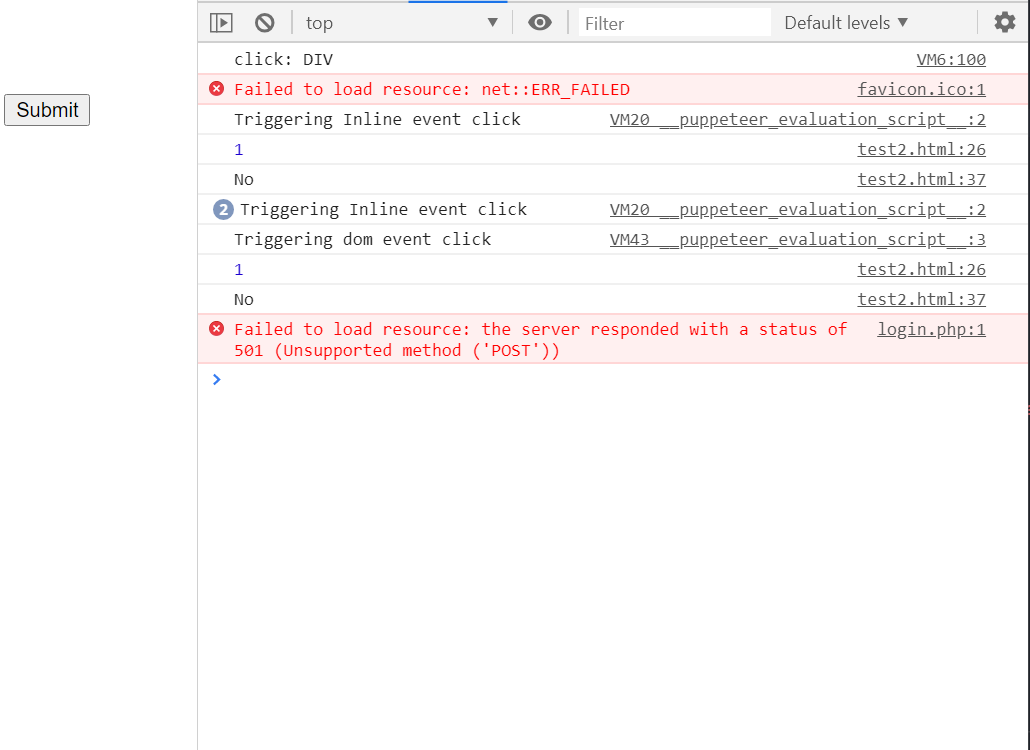
入队 && url去重
上述所有操作做完后,应该就收集到足够多的url并触发了尽可能多的事件了。把他们入队,cluster就会另外开一个线程继续执行我们的任务。
当然这样就存在一个url判断与去重的问题。对于判断,我是采取只爬输入域名及其子域名的方式,否则不入队;而去重这点就比较重要了,比如我尝试爬了下baidu,结果收集到几百个链接,继续入队后爬的又几乎是重复的url,显然是在做无用功。我目前单针对url很不优雅的解决方案就是用Set数据结构维护独立性。但是假如工程项目的话肯定是要用到redis集合了。不过这样一个简单爬虫应该用不到数据库吧(
Summary
总的来说写这个爬虫主要是锻炼下技术以及实践下文章,可以说还是学到不少知识的。假如这篇文章或者项目有帮到你的地方那就点个star 吧 :)。https://github.com/baiyecha404/Dynamic-Crawler 说不定还可以优化下。
References
https://github.com/LFYSec/CrawlerNode https://github.com/Passer6y/CrawlerVuln https://github.com/myvyang/chromium_for_spider https://www.anquanke.com/post/id/178339 http://blog.fatezero.org/2018/04/09/web-scanner-crawler-02/
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
